开yunapp体育官网入口下载手机版 人工智能跨界二次元,日本游戏公司用GAN生成高分辨率动漫人物
《Rake World》合辑:呀~是阿童木、卡布达、EVA
简介:熟悉二次元的朋友一定对动漫人物的服装变化和姿势变化很熟悉。最近,日本网络服务公司 DeNA 提出了渐进结构条件生成对抗网络(PSGAN),这是一种可以根据姿势信息生成全身图像的新框架。以及动漫人物的高分辨率图像。接下来,我们来看看PSGAN是如何生成全身动漫角色并为其添加新的姿势和动作的。
具有分层和渐进结构的生成对抗网络(GAN)的最新进展使得生成高分辨率图像成为可能。然而,现有方法在生成对工业应用很重要的结构化对象(例如全身图形)方面存在局限性。另一方面云开·全站app登录网页入口,虽然已经提出了可以基于结构化条件(例如姿势和面部标志)生成图像的 GAN,但它们的图像质量还不够。为了解决上述限制,我们引入了PSGAN,它在训练过程中使用结构化对象来逐渐提高生成图像的分辨率,以生成结构化对象(例如全身人)的详细图像。此外,我们在网络上施加任意潜在变量和结构条件,以根据目标的姿势序列生成不同的可控视频。在本文中,我们通过实验证明了这种方法的有效性,展示了 512x512 视频生成的实验结果,其中包含详细的、姿势调节的动漫角色。
生成结果概述
我们展示了 PSGAN 生成的各种动漫角色和动画的示例。我们首先使用 PSGAN 从随机潜在变量生成许多动漫角色。接下来,我们通过插入与动漫角色对应的潜在值来生成新的动漫角色。然后开yun体育app入口登录,使用连续姿势序列生成内插动漫角色的动画。
生成新的全身动漫角色
我们通过使用 PSGAN 插入与不同服装的动漫角色(角色 1 和 2)相对应的潜在值来生成一个新的全身动漫角色。请注意,此处仅施加一种姿势条件。

为生成的动漫角色添加动作
下面显示了具有指定动漫角色和目标姿势的动画生成示例。
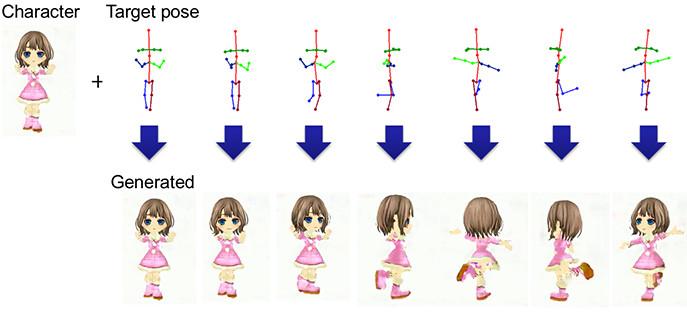
通过修复潜在变量并为 PSGAN 提供连续的姿势序列,我们可以生成角色动画。更具体地说,我们将给定动漫角色的表示映射到潜在空间中的潜在变量,作为 PSGAN 的输入向量。
通过将指定的动漫角色映射到潜在空间并生成潜在变量作为 PSGAN 的输入,生成具有指定动漫角色的任何动画。
最近,科学家们进行了利用深度生成模型自动生成图像和视频的研究。可以说,这些研究对照片编辑、动画和电影制作等媒体创作工具具有重大意义。
专注于动漫创作,自动角色生成可以激发专家创作新角色的灵感,同时也有助于降低绘制动画的成本。
由Yanghua Jin、Jiakai Zhu、Minjun Li、Yingtao Tian、Huachun Zhu撰写的《使用生成对抗网络生成高质量动画角色》重点介绍了使用GAN架构来实现动画角色脸部的图像生成。然而,全身角色生成尚未被提出。
可以说,专家提出的是生成只注重面部图像的动画人物图像,但其质量并不能满足动画制作的要求。
自动生成全身角色并为其添加高质量的动作,这对于制作新角色和绘制动画非常有帮助。因此,我们致力于生成全身人体图像并为其添加高质量的运动(例如视频生成)。
将全身角色生成应用于动画制作仍然存在两个问题:(i)高分辨率生成,以及(ii)特定姿势序列生成。
可以说,作为适合各种图像生成任务的框架,生成对抗网络(GAN)是最有前途的候选方法之一。具有分层和渐进结构的 GAN 的最新进展使得高分辨率、详细的图像合成和文本到图像的生成成为可能。然而,高质量生成的应用仍然仅限于某些对象,例如人脸和鸟类。生成具有全局结构的结构化对象对于 GAN 来说是一个巨大的挑战,对于高分辨率的生成也是如此。另一方面,科学家们还提出了具有结构化条件(例如姿势和面部标志)的 GAN。然而,它们的图像质量还有很多不足之处。
我们提出渐进结构条件生成对抗网络(PSGAN)来解决这些问题。我们证明 PSGAN 能够生成具有 512x512 分辨率的目标姿势序列的全身动漫角色和动画。当 PSGAN 生成具有潜在变量和结构条件的图像时,PSGAN 能够生成具有目标姿势序列的可控动画。
渐进式结构条件 GAN
我们的主要想法是逐步学习结构条件图像表示。 PSGAN 提高了每个尺度上具有结构条件的生成图像的分辨率,并生成具有详细姿态条件的高分辨率图像。我们采用与 Zizhao 张、Yuanpu Xie 和 Lin Yang 的“使用分层嵌套对抗网络的摄影文本到图像合成”中相同的图像生成器和鉴别器架构,除了我们提出的姿态图分辨率,在每个尺度的生成器和鉴别器。
利用所提出的网络架构,通过相应的条件图从低分辨率层到高分辨率层逐步执行图像生成,这显着稳定了训练。这一添加使得能够在每个 NxN 分辨率下训练的生成器和鉴别器结构进行渐进式结构调节,并稳定结构条件生成的训练。
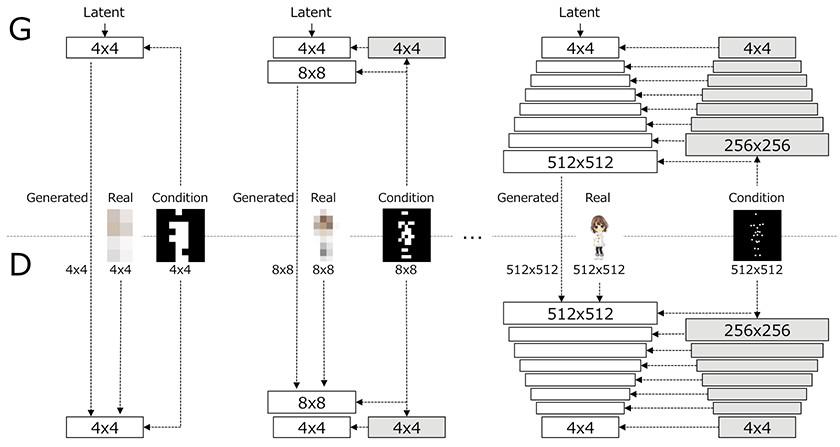
PSGAN 的生成器 (G) 和鉴别器 (D) 架构。 NxN 白框表示以 NxN 空间分辨率运行的可学习卷积层。 N×N灰框代表结构条件的不可学习的下采样层,它将结构条件图的空间分辨率降低到N×N。
训练数据准备
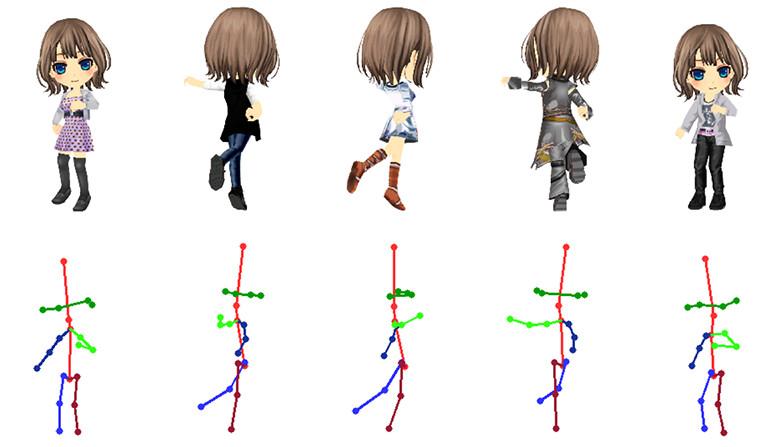
在本节中,我们描述我们的数据集准备方法。对于 PSGAN,我们需要成对的图像和关键点坐标。我们准备了Unity合成的原始头像动漫人物数据集,以及Openpose检测的关键点DeepFashion数据集。
阿凡达动漫人物数据集
我们构建了一个新的 PSGAN 数据集来满足三个要求:
1.姿势的多样性。为了生成流畅自然的动画开yunapp体育官网入口下载手机版,我们准备了多种姿势条件。
2.训练图像的数量。通过使用Unity生成3D建模的虚拟化身,可以获得无限数量的带有关键点贴图的合成图像,而无需任何手动注释。
3.背景去除。我们将背景颜色设置为白色并删除不必要的信息,以避免对图像生成产生负面影响。
我们将一个变换的几个连续动作分成 600 个姿势,并捕获每个姿势的关键点。我们对 79 件服装进行了此操作,总共生成了 47,400 张图像。我们还根据 3D 模型的骨骼位置获得了 20 个关键点。
下图显示了训练数据的示例。动漫人物(顶行)和姿势图片(底行)。
DeepFashion数据集
PSGAN 利用姿态信息对图像生成网络施加结构条件。我们使用 Openpose 从没有关键点注释的图像中提取关键点坐标。关键点数量为18个,检测到的关键点少于10个的样本被忽略。缺失的键用-1填充,其他键设置为1。
训练设置实验
我们使用与 GAN 的渐进式增长相同的阶段设计和损失函数来提高质量、稳定性和多样性。我们展示了鉴别器每个阶段的 600K 真实图像和结构条件,并使用 n_critic=1 的 WGAN-GP 损失。为了节省CPU内存,在4×4-128×128图像生成阶段,我们将minibatch大小设置为16,并将256×256图像和512×512图像的生成器分别减少到12和5。
我们用M个通道来表示M个关键点的结构条件。在每个通道中,一个像素在相应的关键点处填充1,在其他位置填充-1。对于每个 N×N 分辨率,我们使用内核大小为 2、步长为 2 的最大池化作为结构条件缩减层。
阿凡达动漫人物数据集:我们使用 Adam 来训练网络,其中 β1=0,β2=0.99。我们在4×4-64×64图像生成阶段使用α=0.001,并逐渐将其减少到对于128×128图像来说α=0.0008,对于256×256图像来说α=0.0006,对于512×512图像来说α=0.0002。姿势关键点的数量为20。
DeepFashion数据集:我们使用Adam(α=0.0008,β1=0,β2=0.99)来训练每个阶段的网络。位姿通道数为 18。
PSGAN、PG2、Dinentange PG2 和 Progressive GAN 的比较
在本文中,我们研究了 PSGAN 生成的图像的多样性。下图显示了 PSGAN 生成的图像,其中潜在变量是随机设置的。 PSGAN 为每个姿势条件生成各种各样的图像。

接下来,我们使用姿势引导人物图像生成(PG2)和解缠结人物图像生成(DPG2)来评估 PSGAN 的再现性。进行了比较。 PG2和DPG2需要源图像和相应的目标姿态,将源图像转换为具有目标姿态结构的图像。同时,PSGAN 根据潜在变量和目标姿态生成具有目标姿态结构的图像。与PSGAN相比,PG2和DPG2更容易受到源图像和相应目标位姿的影响。
下图显示了PSGAN、PG2和DPG2的生成图像。我们省略了 PG2 和 DPG2 的输入图像。由此我们可以观察到PSGAN生成的图像与PG2和DPG2生成的图像一样自然、真实。由于 PSGAN 也从潜在变量生成图像,因此理论上,PSGAN 可以生成 PG2 和 DPG2 等多种图像。

最后,我们评估 PSGAN 与渐进式 GAN 的结构一致性。下图是渐进式GAN和PSGAN生成的图像的比较。我们发现渐进式 GAN 无法生成由其整体结构组成的结构对象的自然图像。另一方面,PSGAN 可以通过对每个度量施加结构条件来生成由其整体结构组成的近乎真实的图像(例如:左侧的两个图像)。

综上所述
本文演示了 PSGAN 生成的流畅、高分辨率的动画。我们证明 PSGAN 可以基于 512×512 目标姿势序列生成全身动漫角色和动画。在训练过程中,PSGAN可以通过改善每个尺度的结构条件来逐渐提高生成图像的分辨率,并生成结构化物体的细节图像(例如:全身人物)。由于 PSGAN 生成的图像具有潜在向量和结构条件,因此 PSGAN 能够生成具有目标姿势序列的可控动画。我们的实验结果表明,PSGAN 可以基于随机潜变量生成各种动画角色,并使用连续的姿势序列作为结构条件,使动画更加流畅。由于实验环境有限,例如一个头像和多个动作,我们计划在不同条件下继续进行实验和评估。
未来,我们计划开发 Avatar Anime-Character 数据集。
原文链接:
 鲁ICP备18019460号-4
鲁ICP备18019460号-4
我要评论